在數據驅動的時代,企業對數據時效性的要求日益嚴苛,實時數據倉庫的建設已成為企業數字化轉型的核心競爭力。2023年,隨著技術的演進與業務場景的深化,實時數倉的建設思路、數據處理模式以及存儲支持服務都呈現出新的趨勢與最佳實踐。本文將深入解析實時數倉建設的關鍵環節,聚焦于數據處理與存儲支持服務,為構建高效、穩定、可擴展的實時數據平臺提供詳盡的指南。
一、實時數倉建設概覽:從理念到架構
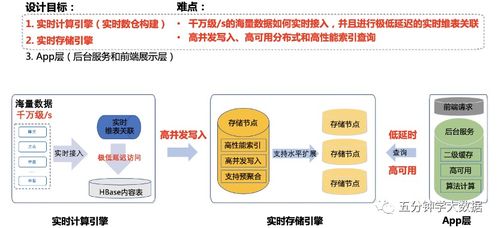
實時數倉并非簡單的“將批處理變快”,而是一套旨在支持低延遲數據攝入、處理、分析與服務的系統性工程。其核心目標是縮短數據從產生到產生業務價值的“時間差”,通常要求端到端延遲在秒級甚至毫秒級。2023年,主流架構已從早期的Lambda架構,普遍演進為更簡潔、統一的Kappa架構或流批一體架構。
- Kappa架構:以統一的流處理為核心,所有數據被視為流,歷史數據通過重放流來重新處理。它簡化了技術棧,避免了批流兩套系統帶來的復雜度與一致性難題,但對消息隊列的存儲能力與流處理引擎的狀態管理提出了更高要求。
- 流批一體架構:得益于Apache Flink等引擎的成熟,流批一體成為現實。開發者可以使用同一套API進行流處理和批處理,底層引擎自動適配執行模式。這極大地統一了開發體驗,降低了運維成本,是當前技術選型的主流方向。
一個典型的實時數倉技術棧包括:數據采集層(如Kafka, Pulsar)、實時計算層(如Flink, Spark Streaming)、數據存儲層(如OLAP數據庫、數據湖)以及數據服務層(如API網關、查詢引擎)。
二、實時數據處理:流計算的精粹
數據處理是實時數倉的“心臟”。2023年的實踐強調高吞吐、低延遲、Exactly-Once語義以及強大的狀態管理。
- 數據攝入與連接:穩定、高吞吐的數據源連接是基礎。除了傳統的日志采集(Filebeat, Logstash)與數據庫CDC(Debezium, Canal)工具,云原生場景下,與云服務(如AWS Kinesis, Azure Event Hubs)的無縫集成變得更為重要。
- 核心計算模式:
- 窗口計算:處理無界流的核心,包括滾動窗口、滑動窗口、會話窗口等,用于聚合一段時間內的數據(如每分鐘銷售額)。
- 狀態管理:流計算中維護中間結果(如累計值、去重集合)的關鍵。Flink的托管狀態(Heap/RocksDB)與狀態后端(State Backend)的優化選擇,直接影響到作業的穩定性和性能。
- 流表關聯:實時維表關聯(如流數據關聯MySQL中的用戶信息)是常見需求。通過異步I/O、緩存、廣播狀態等機制進行優化,是降低延遲的關鍵。
- 數據處理質量:
- 一致性保障:通過Checkpoint/Savepoint機制、兩階段提交(2PC)連接器,實現端到端的Exactly-Once處理語義,確保數據不重不漏。
- 亂序數據處理:通過水印(Watermark)機制和允許延遲(Allowed Lateness)策略,有效處理網絡等原因造成的亂序數據,保證計算結果的準確性。
三、存儲支持服務:多元化與分層化
實時數倉的存儲不再是單一數據庫,而是根據數據熱度、查詢模式、成本等因素形成的分層存儲體系。
- 實時數據層(ODS/DWD):
- 消息隊列:如Apache Kafka,既是數據傳輸的管道,也常作為原始數據的短期存儲(基于日志壓縮主題存儲全量快照),支持數據重放。
- 實時聚合層(DWS/ADS):
- OLAP數據庫:用于存儲預聚合后的實時結果,支持高并發、低延遲的即席查詢。2023年,ClickHouse(極致性能)、Apache Doris(易用性與實時分析兼備)、StarRocks(極速全場景)等MPP數據庫競爭激烈。云上托管服務(如阿里云Hologres, Google BigQuery)也提供了開箱即用的強大能力。
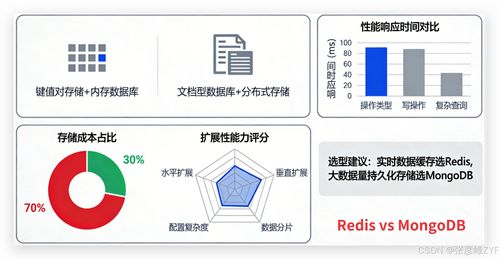
- 鍵值存儲:如Redis、TiKV,用于存儲需要極低延遲訪問的維度表或熱點結果集。
- 數據湖倉一體層:
- 以Apache Iceberg、Apache Hudi、Delta Lake為代表的開放表格式,正成為連接實時流與歷史批的“錨點”。它們支持流式增量寫入、時間旅行查詢、ACID事務,使得在對象存儲(如S3, OSS)上構建兼具數據湖靈活性與數據倉庫管理能力的“湖倉一體”平臺成為現實。Flink等引擎可直接寫入Iceberg表,實現實時數據直接入湖。
四、數據服務與治理:價值交付的最后一公里
存儲的數據最終需要通過服務化方式交付給業務。
- 查詢引擎與API服務:利用Trino/Presto、Apache Druid等對存儲層進行聯邦查詢,或通過GraphQL、REST API將數據封裝成微服務,供前端應用直接調用。
- 實時數據治理:實時場景下的數據治理挑戰更大,需關注:
- 元數據管理:實時作業的血緣關系、Schema變更管理至關重要。
- 數據質量監控:對數據流的延遲、吞吐量、空值率等設置實時監控與告警。
- 資源與成本治理:對Flink作業等計算資源進行細粒度監控與優化,避免資源浪費。
五、總結與展望
2023年的實時數倉建設,呈現出 “流批一體架構普及、存儲分層化與湖倉一體化、云原生與托管服務深度融合” 三大特點。成功的關鍵在于根據業務場景(如實時風控、實時推薦、監控告警)選擇合適的技術組合,并持續關注數據處理管道的健壯性、數據存儲的查詢效率以及整體架構的運維成本。隨著人工智能對實時特征需求的爆發,實時數倉將與特征平臺更緊密地結合,邁向更智能、更自動化的實時數據基礎設施。